

一、大会主题与氛围
2025 年云栖大会在杭州云栖小镇举办,主题是 “云智一体·碳硅共生”。表面上是“云 + 智能”的技术融合,深层含义是碳基生命(人类)和硅基智能(AI)共生进化:
- “云智一体”——强调云平台与智能(大模型、Agent)能力的深度融合,阿里试图把云基础设施、模型能力、Agent 开发平台、工具链合并为“企业级 AI 原生栈”。
- “碳硅共生”——从宏观上表达“以人(碳基)与机器/硅基智能协同”的长远愿景(大会演讲中也多次谈到“人机协作”、“AI 扩大人类能力”的话题,吴泳铭提出 AGI/ASI 的长期视角)。
大会规模与参与者非常多元:三大主论坛、110+ 场聚合话题、4 万平米展区、500+ 家参展企业,观众覆盖传统行业企业 CIO、开发者、学术界、以及更广泛的社会群体(大会也呈现出更强的社会化参与气氛)。现场依旧人山人海,开发者、企业客户、学者云集之外,今年多了很多不一样的面孔:退休老人、小学生、外国游客。说明 AI 已经不再只是技术圈的话题,而是进入了社会大众的生活。
展馆分为三大板块:
- 人工智能馆:大模型、Agent、AI 应用体验;
- 计算馆:算力、存储、绿色数据中心;
- 前沿应用馆:行业解决方案与创新实践。
二、大会五大核心亮点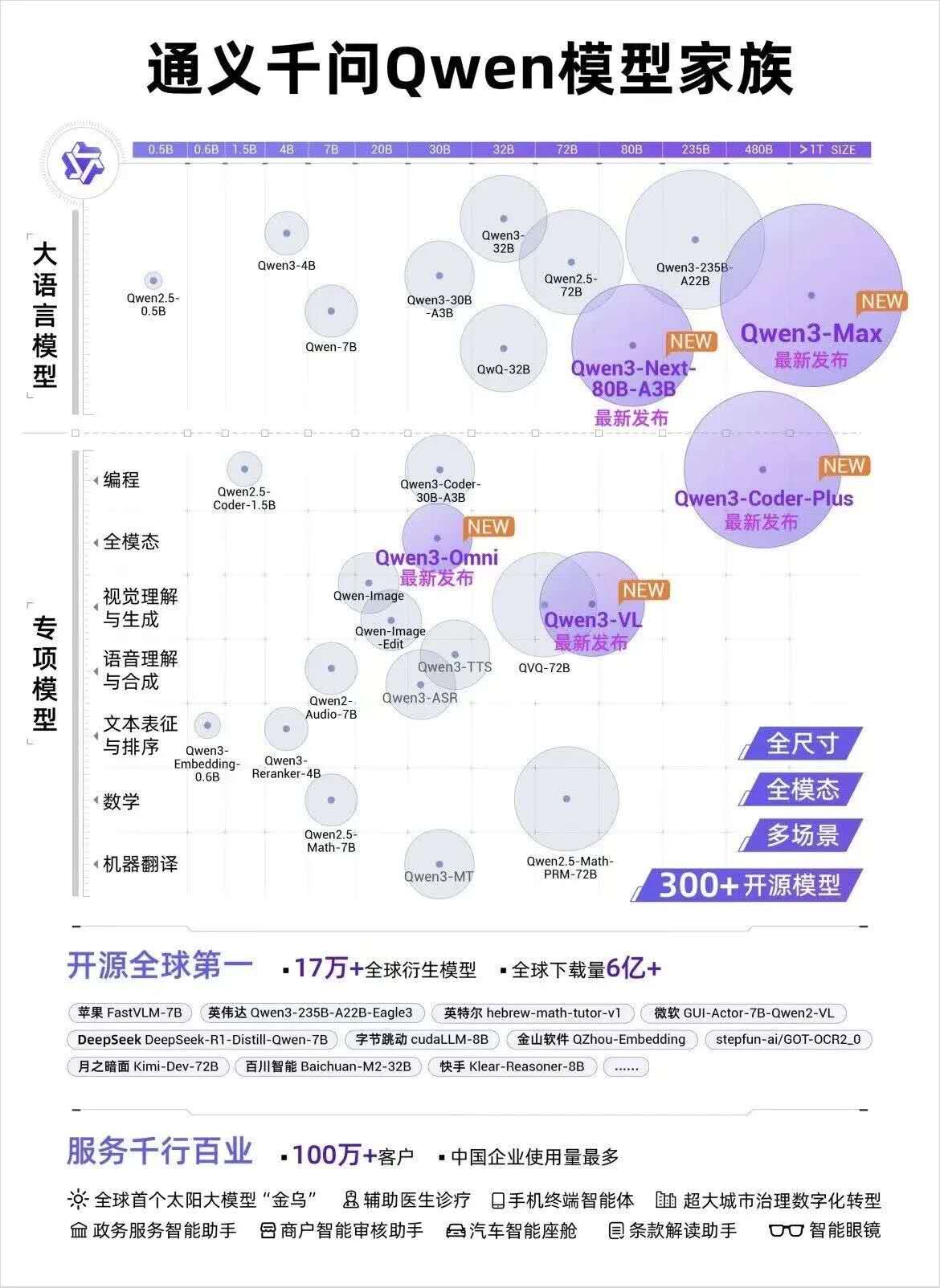
- 发布7款新模型及通义 Qwen3-Max 发布
- 阿里最新的旗舰大模型,万亿参数、多模态(文本、图像、语音、视频、代码全覆盖),继续坚持“开源 + 多尺寸”路线。
- 目标不仅是比拼参数,而是构建起多模态、可扩展、可用的企业级生态。
- 基础设施全面升级
- 硬件:磐久 128 超节点服务器。
- 网络:HPN 8.0、UALink 协议,单集群支撑 10 万卡 GPU,带宽可达 6.4Tbps。
- 能源:绿色数据中心、AI 原生机房设计,强调可持续。
- 存储与成本优化
- OSS Vector Bucket:专为向量数据优化,存储成本下降至原来的 1/10。
- CPFS 并行文件系统吞吐再提升,面向大规模训练场景。
- Agent 平台走向生产化
- 百炼平台、ModelStudio-ADP/ADK 提供低代码/高代码双轨开发能力。
- 案例:网商银行贷款审核,26 种凭证识别准确率达 95%,审核时间从 3 小时降到 5 分钟,已进入生产。
- 说明 Agent 已经跨过“演示阶段”,正成为业务落地的最小执行单元。
- 生态与合作
- 与 NVIDIA 在具身智能(Physical AI)展开合作。
- 与 SAP、德勤在企业级应用、行业咨询方面深度结合。
- 显示出“AI 不只是云服务”,更是跨界生态的结合点。
三、架构分层理解
基于大会日程与发布,阿里的“全栈AI技术体系”分为四层,供企业对照评估其自身架构成熟度与演进路径。
A. 基础设施层(Infrastructure)
- 超节点服务器(磐久 128/144 超节点):高密度单柜支持数十/百个AI计算芯片、集成阿里自研 CIPU 2.0 与高性能网卡,目标是 Scale-Up/Scale-Out 混合的超大集群。
- 高速互联与网路(UALink / HPN 8.0):面向训练与推理的训推一体化网络,GPU 互联带宽 / 存储带宽均大幅升级(媒体报道中提到 GPU 互联可达多 Tbps、存储网络带宽拉升至 800Gbps 等指标)。UALink 被提出为开放高速互连标准以支持千级加速器互联。
- 分布式存储面向AI:CPFS(并行文件系统)在吞吐与并发上做了针对性优化,OSS 增加了面向向量数据的 Vector Bucket(计费与存储设计使向量存储成本显著下降,大规模向量化场景更经济)。
B. 平台与模型层(Platform & Models)
- 通义千问(Qwen)家族扩展:Qwen3-Max、Qwen3-Next 等多模态 / 大参数模型并行发布,覆盖文本、图像、语音、视频、代码等能力。阿里强调开源生态(通义系已开源数百模型并被大量下载/衍生)。
- 百炼(ModelStudio / ModelStudio-ADP/ADK):集模型服务、Agent 开发、低代码/高代码并行的企业级平台,支持模型部署、工具调用、记忆存取、沙箱与安全隔离等企业级能力。
C. 开发范式与中间件(Development Paradigm)
- Agentic 开发范式:ModelStudio-ADK(高代码)和 ADP(低代码)组成高/低代码并行的工具链,旨在缩短从模型到业务Agent的落地时间(宣称“1 小时可搭建深度报告 Agent”作为能力示例)。
- Agent Infra 与执行沙箱(无影 AgentBay / Agentic Computer):支持分布式执行、工具链接入、内存状态管理、安全围栏等,为 Agent 在生产环境的可控执行提供底座。
D. 行业应用层(Application & Industry)
- 大量行业解决方案与落地:金融(例如工商银行/网商银行的模型化与 Agent 应用)、制造、医疗、教育、零售等均在现场展示或分享案例(网商银行的小微贷审核是典型生产级示例)。
四、值得关注的行业案例
- 金融:网商银行贷款审核
Agent 自动识别并验证 26 种凭证,审核时间缩短 95%,准确率接近人工水准。核心意义在于:Agent 可以串联 OCR、模型、流程引擎、合规审计。小微贷款审核 Agent — 基于 ModelStudio-ADP/ADK 构建的 Agent 能识别 26 种凭证、400+ 细粒度物体,准确率 ~95%,将人工审核时长从 ~3 小时缩短至 ~5 分钟(面向小微贷的自动化审批)。这是 Agent 在金融合规场景的生产级落地示例。 - 制造业与具身智能
与硬件厂商合作探索仿真—训练—部署闭环,未来机器人与自动化系统会是重点场景。 - 教育 / 医疗
多用于辅助决策,因合规要求高,短期以试点为主。 - 具身智能 / Physical AI 场景
与 NVIDIA 的合作指向机器人、仿真、自动驾驶与工业仿真等需要物理世界交互的场景,意味着“模型+仿真数据+物理引擎”的组合将是未来若干重要落地路径。
五、技术趋势(五个关键词)
- 从“模型中心”到“Agent 中心”:模型是能力源,Agent 才是交付价值的单元。
- 全栈协同:算力、存储、模型、工具链、应用要一体优化。单点突破已经不够。
- 向量化与成本下降:向量检索成本大幅下降,RAG 将成为 AI 落地的标配。
- 开源与生态:阿里推动开源模型与社区,企业将有更多选择空间。
- 安全与合规:Responsible AI 成为常态,企业必须同步建设治理框架。
六、对企业 IT 的行动建议
优先级一:立即行动(0–6 个月)
- 数据梳理与分类(必做)
- 建立数据目录、数据质量检查与元数据治理(为后续 RAG 与 Agent 提供可信数据源)。关键指标:数据目录覆盖率、敏感数据发现率、数据检索延迟。
- 做一个小规模 RAG POC(向量化 + OSS Vector Bucket)
- 验证向量检索成本、召回效果与检索延迟;优先测试 OSS Vector Bucket(若使用阿里云)或等效云向量存储,关注索引更新延迟与成本。关键指标:每次检索成本、avg recall@k、请求延迟。
- 合规/安全基线:建 Token / 密钥管理、数据脱敏/脱标、审计链(Agent 的每次工具调用需可溯源)。
(对上面建议的视觉化优先级图我已生成,见下方下载链接。)
优先级二:试点与扩展(6–18 个月)
- Agent 试点(ModelStudio-ADK/ADP + 无影 AgentBay)
- 选择 1–2 个业务线(如客服自动化、采购审批、贷款初筛)做 Agent 试点。推荐采用高/低代码并举:复杂场景用 ADK,高复用流程用 ADP(低代码)。参考网商银行案例作为落地路径。
- 算力/架构评估:评估是否采用云端托管(混合云优先)或租用私有超节点(若有高并发推理需要),并测试延迟与成本曲线。参考 HPN/UALink/超节点的容量规划思想。
- 建立模型治理与评测管线:不仅关注模型准确度,还量度工具调用安全、记忆一致性、模型漂移与可解释性。
优先级三:规模化与长期(18+ 个月)
- 生产化 Agent 编排与 SRE 体系:Agent 的链路复杂度更高,需要事务管理、回滚策略、异常补偿、定期红队测试和 SLA/ SLO 体系。
- 长期投资:边缘/具身智能与物理AI实验(若适用)——针对制造/机器人/车企类客户,考虑与云与第三方(如 NVIDIA)共同投资仿真与物理 AI 流程。
七、风险与挑战
- 数据泄露:Agent 工具调用风险高,必须加权限控制和审计。
- 模型漂移:风控/医疗等场景必须有回溯机制。
- 成本失控:模型调用与向量存储需严格预算与监控。
- 法规合规:尤其国际业务,数据主权与隐私问题必须提前处理。
- 数据泄露与知识泄露:Agent 调用外部工具与检索内部知识库时,需要强审计、权限隔离与严格的 RAG 检索审查。
- 可解释性与合规:金融/医疗/监管强行业须建立可审查的决策链路(Agent 的每个步骤要有“证据”)。
- 成本失控:大模型调用和高并发推理会带来可观费用,采用向量桶、缓存与异步设计降低成本。
- 组织能力与变革阻力:AI 并不是解决所有问题的银弹,强调“问题定义能力”与“业务创新能力”的培养比仅招聘模型专家更重要。

八、经典言论与体会
- 吴泳铭(阿里巴巴 CEO):“大模型是下一代操作系统,超级AI云是下一代计算机;AI 有望替代能源成为最重要的商品(Token 将是未来的电)。” —— 这类表述既是愿景表态,也在引导生态与资本对“算力+模型+应用”重构的长期预期。
- 周靖人(阿里云 CTO / 通义负责人)在技术发布会上强调通义家族的“开源+多模态+Agent 能力”并展示了 Qwen3 家族的一系列能力与开源生态数据。
- 王坚: AI不是大脑, 它只是这个时代的纸和笔
- 技术门槛正在下降,未来拼的不是“谁的模型更大”,而是“谁能把业务和 AI 融合得更好”。
- 创意和场景定义比技术本身更珍贵。
- 从老人到小学生都在接触 AI,说明企业也需要更多关注社会责任与公众接受度。
- 技术民主化正在发生:从大会现场看到从退休老人到学生、行业从业者与外国观众参与,说明技术传播与普及正在扩展到更宽的受众层(这是“科技平权”的社会证据)。(此部分为现场观察与体验)
- 互联网企业下沉行业,传统行业抓住 AI 的“工具化”优势:互联网公司更懂业务与跨界,而传统行业通过 Agent/模型可以有效降低技术门槛——但真正的稀缺是行业知识与创意的结合。
- 不盲目追“大模型”:对企业而言,正确的问题是“这个模型/Agent 能否解决业务关键点并可持续运维”,而不是纯粹追求最大模型。把重点放在数据质量、检索与执行可靠性上,往往比“换模型”更有效。
九、结语
2025 云栖大会释放的信号很明确:AI 已经从“炫技”转向“落地”。阿里正试图用全栈架构把自己打造成 AI 时代的“操作系统”。
对企业 IT 架构师来说,真正要问的问题不是“阿里又发布了什么大模型”,而是:
“我能不能在半年内做一个小型 RAG + Agent POC,把它跑通并证明价值?”
- 先数据后模型:先把数据底座、元数据、权限与审计做好,再做模型与 Agent 的扩展。
- 做小而快的 RAG + Agent POC:验证成本、延迟、准确率、合规路径,形成可复用框架。
- 设立治理与 SRE 标准:Agent 生产化需要可观测性、审计与回退机制。
- 关注生态合作:与云厂商/行业软件、行业咨询等合作伙伴形成联合方案,快速把技术转为业务产出。
