
一、大数据之应用
大数据是以容量大、类型多、存取速度快、应用价值高为主要特征的数据集合,正快速发展为对数量巨大、来源分散、格式多样的数据进行采集、存储和关联分析,从中发现新知识、创造新价值、提升新能力的新一代信息技术和服务业态。通过采集数据资源,并对数据加以整合、分析、提取,得到有价值的信息,企业运营者可更清楚了解企业的运营现状并做出预判,让企业决策更高效精准。对企业而言,大数据是一种管理思维,支点在于企业内外部数据信息的融合,可呈现出企业的组织形态、运作方式和价值创造模式。因此,在企业发展道路上,大数据的核心应用价值是管理模式的改变与创新。
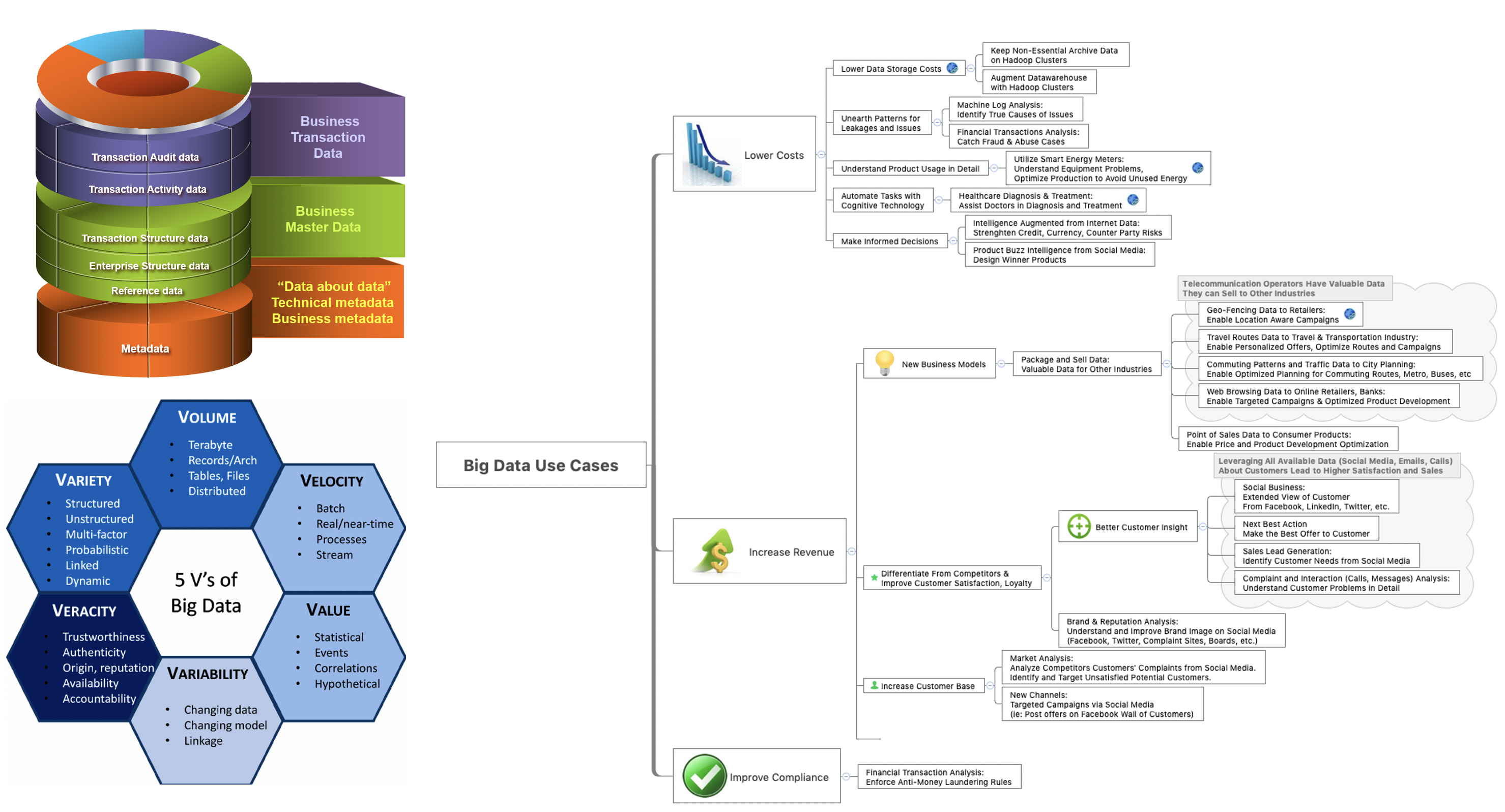
随着大数据的应用越来越广泛,应用的行业也越来越低,我们每天都可以看到大数据的一些新奇的应用,从而帮助人们从中获取到真正有用的价值。很多组织或者个人都会受到大数据的分析影响,但是大数据是如何帮助人们挖掘出有价值的信息呢?下面就让我们一起来看看九个价值非常高的大数据的应用,这些都是大数据在分析应用上的关键领域:
- 理解客户、满足客户服务需求
- 业务流程优化
- 大数据正在改善我们的生活
- 提高医疗和研发
- 提高体育成绩
- 优化机器和设备性能
- 改善安全和执法
- 改善我们的城市
- 金融交易
以上九个是大数据应用最多的九个领域,当然随着大数据的应用越来越普及,还有很多新的大数据的应用领域,以及新的大数据应用。
二、企业数据之现状
1. 企业应用:数据沼泽企业海量的数据宝藏通常隐藏各个软件系统中,或者埋没在个人电脑和文件柜里,无法施展能量。它停留在各个业务部门的内部,保存数据的部门可能无法意识到自己的数据,对于另一个部门、甚至整个公司的价值。再比如现在新兴的人工智能技术,如果没有足够的数据来支持AI模型,是无法提供企业期望达到的算法服务的。要使用数据来驱动企业,创造价值,它必须变得可见且易于访问。

2. 数据孤岛: 企业发展到一定阶段时,各个部门各自存储数据,部门之间的数据无法共通,这导致这些数据像一个个孤岛一样缺乏关联性。 (最终常常因为难以流通和利用而变成死数据)
数据孤岛又分为以下两种类型:
-
- 逻辑性数据孤岛:不同部门站在自己角度定义数据,使得相同数据被赋予不同含义,加大了跨部门数据合作的沟通成本。
- 物理性数据孤岛:数据在不同部门相互独立存储,独立维护,彼此间相互孤立。
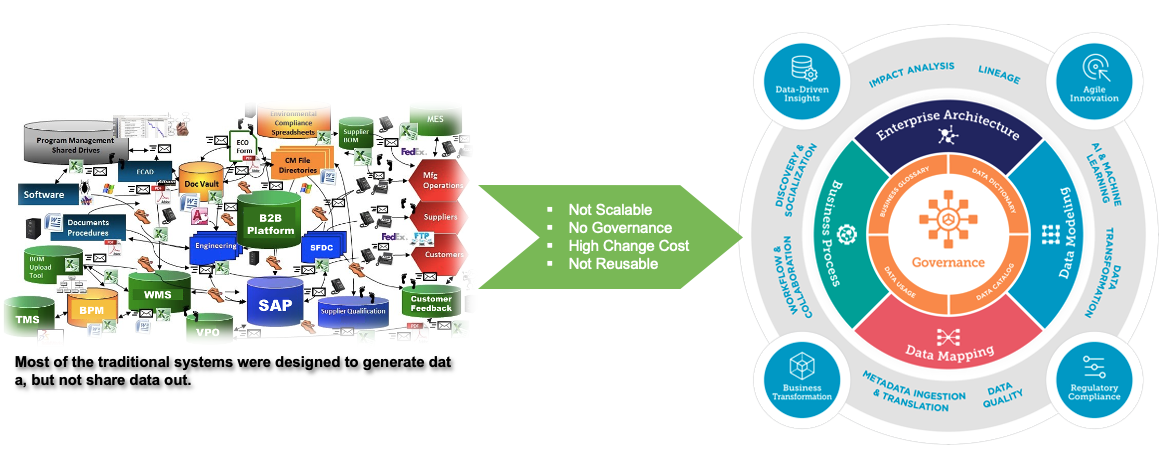
三、企业数据应用挑战
- 数据人才缺乏: 在大数据时代,缺乏专业的大数据人才成为企业面临的最大挑战,大数据的相关职位需要的是复合型人才,能够对数学、统计学、数据分析、机器学习和自然语言处理等多方面知识综合掌控。
- 数据安全与合规:所有企业采集、存储数据最终都是为了有效使用和流转以换取经济利益。因此,数据在使用和流转过程中的合规问题,应是企业数据合规的重中之重。
四、企业数据平台建设方案
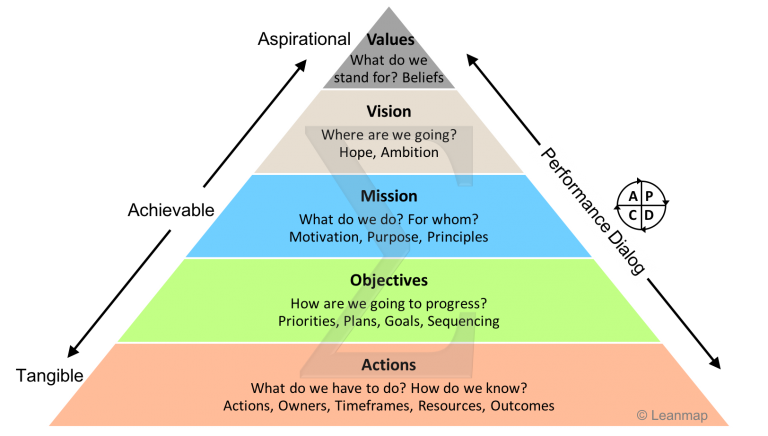
- 战略先行: 战略,是一种从全局考虑谋划实现全局目标的规划,通过制定高级别的行动方案来实现高层次的目标。数据战略是针对数据的管理计划,是规范数据、提高数据质量、保证数据完整性和安全性的计划。数据战略基于对业务数据的理解之上,达成企业的业务目标,从而支撑数据管理,促进数据的应用和服务。企业决策者在制定大数据战略时,需要从Vision(视野)、View(观点)、Value(价值)这“3V”入手。
- 从视野讲,企业CEO一定要把大数据、云计算作为企业核心战略,而不能仅仅把大数据当成是企业IT管理的一个方面。要下决心投入,无论软件方面还是硬件设施。
- 要有企业自己的观点,即收集和处理数据的策略。
- 价值,要在确定思路后,把对数据的分析,转化为能解决实际问题的执行,从而实现大数据的价值。
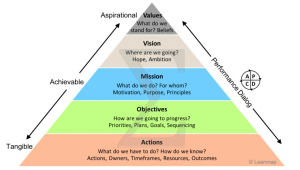
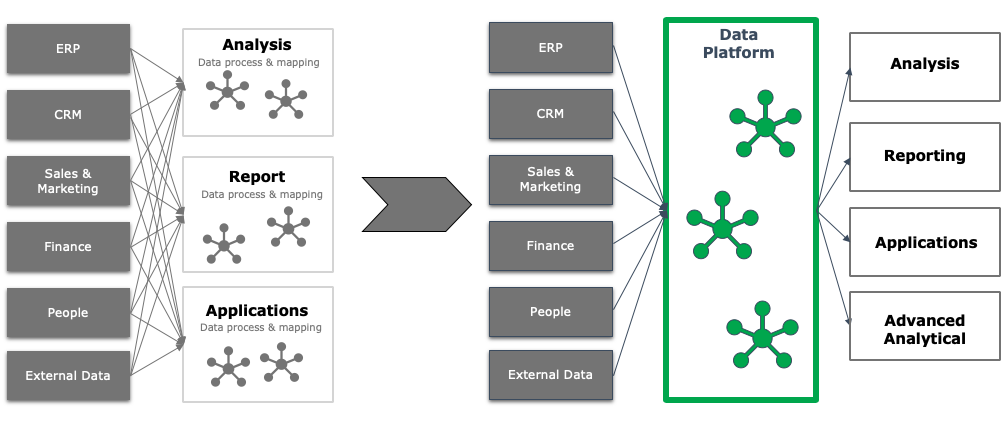
- 数据平台化: 无论是Data Hub, Data Warehouse, Data Lake还是数据中台,其核心还是实现企业数据集中化,标准化的数据处理平台。借用 GrowingIO CEO Simon 的理念,企业如同人类建立的水资源使用系统,而数据如水。企业数据平台的建设目标,应当是让数据像水资源一样在企业中流动。
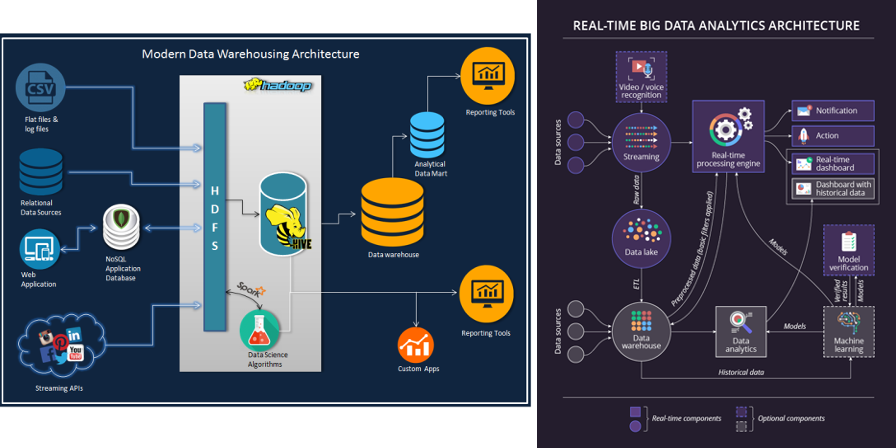
- 架构标准化: 基于通用的数据处理流程,可将企业大数据平台概括为6个主要环节。从数据源开始,依次为数据采集、数据处理、数据存储、数据服务、数据展示以及数据质量管理。
主流的三大分布式计算系统:Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。Yahoo的工程师Doug Cutting和Mike Cafarella在2005年合作开发了分布式计算系统Hadoop。后来,Hadoop被贡献给了Apache基金会,成为了Apache基金会的开源项目。Yahoo,Facebook,Amazon以及国内的百度,阿里巴巴等众多互联网公司都以Hadoop为基础搭建自己的分布式计算系统。Spark也是Apache基金会的开源项目,它由加州大学伯克利分校的实验室开发,是另外一种重要的分布式计算系统。它在Hadoop的基础上进行了一些架构上的改良。Spark与Hadoop最大的不同点在于,Hadoop使用硬盘来存储数据,而Spark使用内存来存储数据,因此Spark可以提供超过Hadoop100倍的运算速度。但是,由于内存断电后会丢失数据,Spark不能用于处理需要长期保存的数据。Storm是Twitter主推的分布式计算系统,它由BackType团队开发,是Apache基金会的孵化项目。它在Hadoop的基础上提供了实时运算的特性,可以实时的处理大数据流。不同于Hadoop和Spark,Storm不进行数据的收集和存储工作,它直接通过网络实时的接受数据并且实时的处理数据,然后直接通过网络实时的传回结果。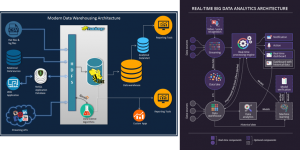
- 数据流程标准化: 面对混杂的数据,不要让您的数据科学家束手无策。 数据平台的主要职责之一就是数据清理和数据处理的自动化,让数据科学家们专注于了解业务数据并进行数据分析。
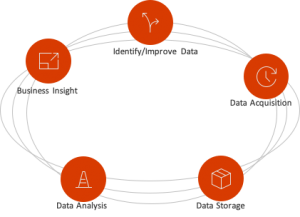
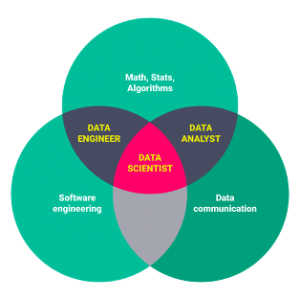
- 数据人才建设: 企业要形成系统化的数据能力,需要不断建设数据团队和培养数据人才,包括数据处理工程师,数据系统工程师,数据科学家,数据分析师等。
- 数据安全评估: 尽管随着科技的发展与信息共享需求的增加,数据的价值日益被得到认可,数据在全球范围内的跨境流动增长迅速也日渐频繁。但与这个趋势相反,各国政府出于国家和社会安全等考虑,更多倾向于对数据出境进行规制与掌控。因此,尽管《评估办法》和《评估指南》还未正式生效,且经过有关机关和部门的斟酌后,不排除现有内容会有所变更可能,但是国家对数据合规的监管趋势不会改变,甚至在监管初期,监管要求与内容大概率是趋严趋紧的。有鉴于此,企业在数据合规方向,特别是跨国企业,应当开始逐渐筹划与组建属于自己的数据合规团队。合规团队应该根据国内外相关法律法规及要求,结合企业自身技术条件、业务需求等内容,系统化、全面化地对企业数据及数据资源进行管理。否则,对数据合规的轻视,不但会使企业陷入合规的泥潭,更可能导致企业错失数据时代的发展机遇。
- 数据治理常态化: 数据治理在系统层面包括数据标准、元数据、数据质量、生命周期管理、数据安全、数据资产共六大核心模块;在管理层面需要通过数据治理组织、数据治理流程进行支撑保障。数据治理是一项长期且复杂的体系化工程,它需要通过一系列流程规范、制度、IT能力以及持续运营等机制来保障治理工作的持续完善和持续推进。

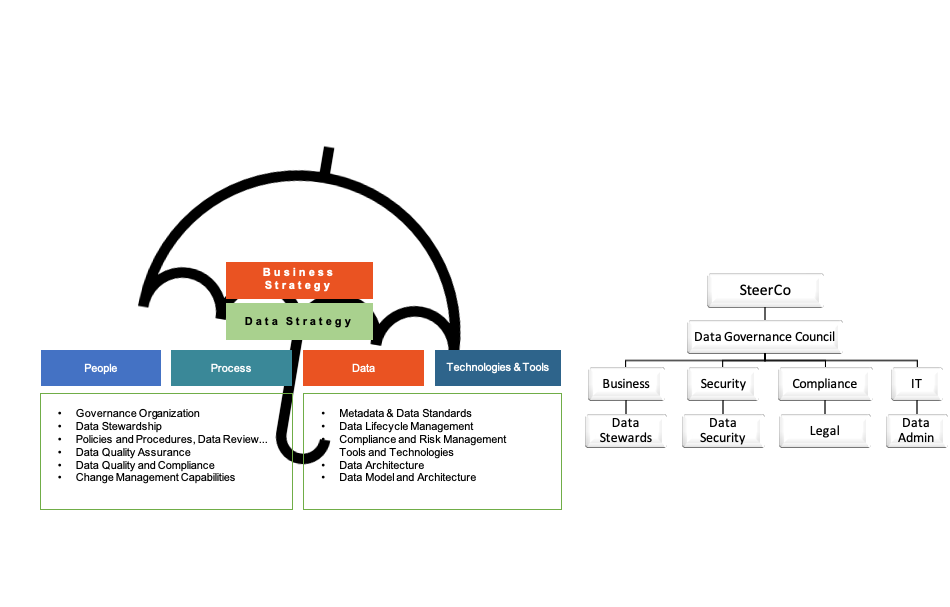
以上内容从了解大数据的价值,到企业的数据现状和数据应用面临的主要挑战分析入手,建议了企业数据平台建议的方案和步骤,通过系统化和标准化的数据平台和数据团队建议,使企业在正确的数据治理和安全规范下,持续性地发挥数据价值,正如谷歌的CFO Ruth Porat所说的 “data is more like sunlight than oil.” 。
