
深度学习革命之路:从 CNN 到 AlexNet
过去几十年里,人工智能领域取得了巨大的进展,尤其是在计算机视觉方面。神经网络——尤其是卷积神经网络(CNN)和深度学习模型——成为了 AI 成就的基石。我们来看看深度学习如何在一批先驱的努力下不断突破,直至推动我们进入今天的 AI 时代。值得一提的是,数据(ImageNet)、算法(AlexNet)、算力(GPU)三者的结合,正是这次 AI 成功的重要推动力。
卷积神经网络的起点
故事要从 1989 年讲起,当时 Yann LeCun,深度学习领域的开创者之一,提出了卷积神经网络(CNN)。LeCun 在大学时受到了“皮亚杰 vs. 乔姆斯基”关于语言学习的争论的启发,最终踏上了智能机器的研究道路。他设计的 LeNet 神经网络在 1998 年 MNIST 数据集上取得了 99.05% 的准确率,这使得少数实验室继续研究 CNN。然而,由于计算资源的限制,CNN 的发展一度停滞。彼时,训练深度 CNN 速度非常慢,且资源消耗极大,大多只能在中央处理单元(CPU)上进行小规模实验。
NVIDIA 的突破:CUDA 平台的诞生
![]()
让深度学习腾飞的关键在于计算能力。早在 1993 年,NVIDIA 创始人黄仁勋和他的团队就发现了 CPU 的局限性。为了提升 3D 游戏的图像渲染速度,他们发明了图形处理单元(GPU)。GPU 可以更高效地处理复杂的数学计算,并行执行成千上万的操作。到 2006 年,NVIDIA 推出了 CUDA 平台,首次将 GPU 应用于通用计算。CUDA 让 C、C++、Fortran 等语言能够利用 GPU 的强大算力,加速复杂计算,从此深度学习研究者们有了新的“玩具”。
2010 年,AI 研究员 Jürgen Schmidhuber 的团队使用 GPU 训练深度神经网络,达到了 CPU 的 50 倍速度,并打破了 MNIST 数据集的记录。同一时期,斯坦福大学的 Andrew Ng 实验室也在试验将 GPU 应用于深度学习。尽管这个决定在当时具有很高的风险,研究者们坚信强大的计算架构可以解决深度学习中的大规模数据和模型训练问题。吴恩达的团队基于 GPU 算力的研究开辟了用 GPU 训练深度学习网络的新方向,为后续的大规模模型提供了强有力的计算支持。
ImageNet:数据的开创性贡献
在深度学习成功的过程中,数据是不可或缺的要素。2007 年,李飞飞教授和她的团队创建了 ImageNet 数据库,这是一个包含数百万张标注图像的数据集,广泛涵盖了视觉识别的多个类别。ImageNet 的出现为研究者们提供了一个前所未有的大规模数据资源,可以用于训练复杂的神经网络。李飞飞的愿景是为 AI 研究提供一个开放的、标准化的数据集,她在创建和标注数据的过程中克服了重重困难,这一开创性的成就极大地推动了深度学习模型的发展,也为 CNN 等视觉识别技术的突破奠定了数据基础。
在 2010 年,ImageNet 启动了大型视觉识别挑战赛(ILSVRC),这是图像识别领域的标杆赛事,为 AI 模型的提升提供了理想的测试平台。ImageNet 的出现不仅推动了算法研究,也开启了深度学习领域对大数据的重视。至此,数据、算法和算力三者的融合逐渐显现。
AlexNet 的突破与深度学习的崛起

让 CNN 和深度学习真正走向大众视野的,是 2012 年 Geoffrey Hinton 团队推出的 AlexNet 模型。Hinton 是 AI 领域的重量级人物,他的学生 Alex Krizhevsky 和 Ilya Sutskever 利用 CUDA 和两块 GPU,将深度神经网络扩展到前所未有的规模。
AlexNet 模型在 ImageNet 数据集上进行了训练,这个数据集包含 120 万张高清图像。AlexNet 使用了五层卷积层和三层全连接层,深度的增加显著提高了性能。为了防止过拟合,他们采用了数据增强技术(如图像平移和水平翻转),并引入了一种名为“dropout”的正则化方法,随机让一些隐藏神经元在训练中失效。这些创新使得 AlexNet 的模型在 ILSVRC-2010 测试集中获得了 37.5% 的 top-1 错误率和 17.0% 的 top-5 错误率,创下了新的记录。
AlexNet 的成功源于几个关键创新:
- ReLU 激活函数:使用 ReLU(线性整流单元)激活函数,加快了深层网络的训练速度。
- 多 GPU 训练:通过跨 GPU 并行化训练,让更大的网络可以同时在两块 GPU 上运行。
- 局部响应归一化:模拟神经元间的竞争行为,帮助模型更好地泛化。
- 重叠池化:使用带重叠的池化层,降低了过拟合风险。
- 数据增强:对图像进行平移、反转和 RGB 通道变化等操作,增加了数据集的多样性。
- Dropout 正则化:通过随机关闭部分神经元,让模型更具鲁棒性。
在 2012 年的 ImageNet 挑战中,AlexNet 取得了 15.3% 的 top-5 错误率,大幅超越当时的第二名(26.2%),这标志着深度学习迈向主流,推动了后续的 VGG、GoogLeNet、ResNet 等模型的诞生。
深度学习革命的配方:算法、数据和算力
总结来看,深度学习革命的“配方”包含以下几种关键元素:
- 大量数据:ImageNet 数据集为研究者提供了一个标准化且庞大的训练数据集。
- 强大模型:AlexNet 在之前研究基础上进一步扩展,展示了深度神经网络的潜力。
- 计算资源:NVIDIA 的 GPU 和 CUDA 平台提供了高效的计算能力,打破了计算瓶颈。
- 坚定信念:一批顶尖研究者的执着推动了 AI 的持续发展,比如李飞飞在构建 ImageNet 数据集时的努力。
最终,这些因素共同推动了 AI 的突破,不仅在图像识别上,还在 NLP 和各类应用中取得了显著成果。AlexNet 的成功为后续的深度学习研究铺平了道路,直接影响了我们今天所见的生成式 AI 革命。
未来的 AI 发展:大模型、应用产品和 AI 操作系统
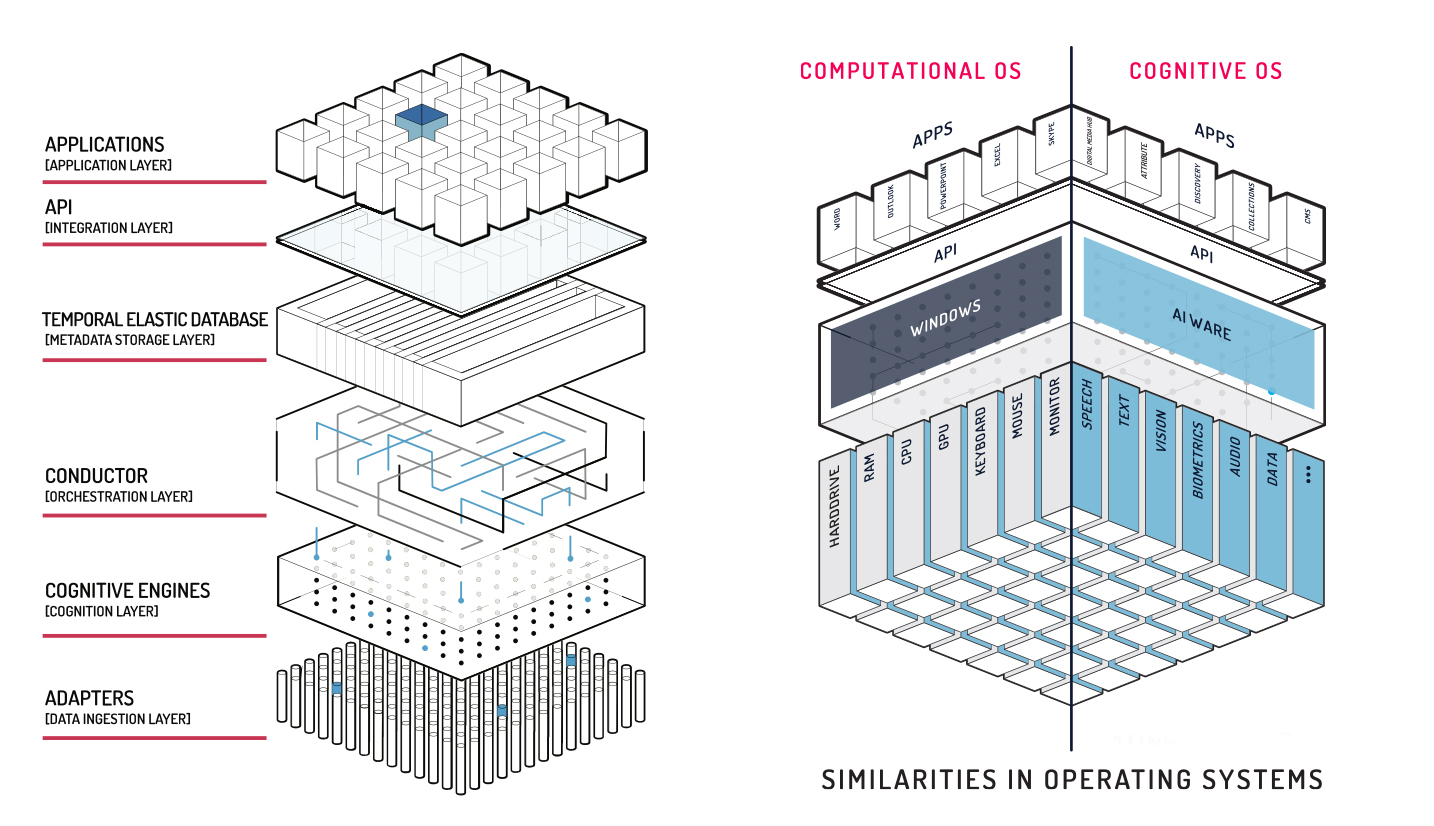
AI 的未来并不只是规模庞大的大模型和创新的应用产品,AI 生态系统的完善可能还需要一个类似操作系统的“中间层”,专门负责管理模型资源、实现通用接口、调度应用资源,并提供跨场景的兼容性。这一“AI 操作系统”层可以集成大模型的底座和多样化的应用产品,为开发者、企业和最终用户提供一个更加高效、完整的 AI 应用平台。这不仅会降低 AI 应用的开发难度,也能更好地支持多模态的 AI 应用和更大规模的数据集成,促进下一代 AI 应用生态的繁荣。
