
“一切都是数据”将成为其必然的趋势。经过了几年的发展和积累,大数据的三个特质越来越明显:量大、多样、实时。对于App应用来说,更多的是在于如何通过数据挖掘改善产品体验、差异化竞争、产生商业价值,达到改善用户体验,增强用户黏性的效果。数据将会是业务的一部分,数据将驱动开发,数据将驱动决策。将来的数据精细化运营,离不开精细、高效的数据统计和分析。这必然会成为一种趋势。本文将就App应用的数据统计分析和埋点技术作些总结和分析。
数据的来源,一般分为前端/客户端数据和后端/服务端数据:
- 对于移动端的App来说, 分析的数据大致上都可以分为俩种, 一种是在线数据,一种是离线数据。 在线数据, 即App后端服务所产生的日志数据,例如服务接口的性能数据, 服务接口的调用及其参数等, 通过服务端的日志数据, 我们不但可以统计服务接口的性能指标,还可以针对具体的业务逻辑,做相关的分析,一些常见的App分析指标如新增,活跃,累计,留存等,也都可以通过服务日志来统计出来。在线日志,一般来讲,有两种:
- Web服务器的配置化log(如Nginx, Apache等Web服务器的access.log):这一类日志不需要用户自己做实现, 只需要开启web服务器的相关日志功能,即可完成日志记录。
- 应用服务器的log:一般包括应用服务器的配置化log 以及 用户自定义的log。 用户自定义log包括用户通过相关日志组件自己的debug, waring ,error, info等级别的日志。 这一类日志没有固定的格式,完全有用户自行控制。在线日志一般会伴随业务直接产生在相关的业务服务器上(web服务器日志产生在web服务器上),但是有的时候,为了将相关服务的监控日志与业务分析日志分离,会将业务日志直接记录在一台独立的日志服务器上。
- 对应的离线数据即是App客户端本身产生的数据, 这种情况一般是发生在客户端不调用底层服务的情况下,需要了解用户在客户端的行为,就需要用到离线数据。 离线日志一般记录用户在客户端的具体行为,如用户在客户端的拖动,上下滚动,翻页等不涉及到后端服务的操作,以及App本身的崩溃行为产生的数据, 都可以被记录, 一般的,记录的内容包括事件类型,控件编号,控件属性及相关参数,事件时间等。离线日志,一般也有两种:
- 客户端的行为日志:用户在操作App的时候,产生的行为,都可以记录下来。 行为日志一般是用来研究用户使用习惯, 分析应用的使用热度的。 同时可以结合客户端异常日志来分析异常原因。
- 客户端的异常日志:用来监控客户端异常原因, 帮助解决相关问题。
目前提供应用统计服务的有2类:
- 通用型:
- Google Analytics
- Apple Store
- 专业型(专业的统计可提供多形式图表,多维度分析比较和高级的筛选功能:时间/渠道/用户/版本维度的筛选):
- Mixpanel
- Flurry
- Localytics
- Google Analytics for Mobile
- GrowingIO
- CNZZ
- Apsalar
- Amplitude
- Heap Analytics
- 计划iO(zhugeio.com)
- 诸葛io
- 神策数据
- 友盟 (错误信息统计,用户反馈统计,与行业数据比较)
- TalkingData
- 百度移动统计
- 腾讯移动分析
开源的有:
- Cobub Razor
- Count.ly
从埋点技术上分,又分为:
- 代码埋点: (SDK:Google Analytics, 百度统计,友盟,TalkingData),成本高,控制精准
- 原理
- 要统计某页面一个Button点击事件次数。首先在APP或者界面初始化的时候,初始化埋点SDK,然后在这个Button事件发生时就调用SDK里面相应的方法,发送接口发送数据
- App端为了避免浪费用户的流量,一般情况下,都是将多条数据打包,并且等待网络状况良好以及应用处于前台时才压缩上传
- 优点
- 控制精准: 可以非常精确地选择什么时候发送数据
- 自定义:随意自定义属性、自定义事件
- 不足
- 人力成本高 > 埋点地方过多,因为不同的版本验证问题不同不易于管理。每一个控件的埋点都需要添加相应的手工代码,不仅工作量大,而且限定了必须是技术人员才能完成
- 版本更新的代价大,易造成埋点混乱 > 每一次更新埋点方案,就意味着必须要修改代码,然后通过各个渠道进行分发,一旦有相当多数量的用户对新版的更新不感冒时,导致埋点代码能够采集到的数据也就得不到更新,前功尽弃,很难在实际日常运营中能够及时依赖实时数据捕获焦点做出应变
- 数据传输的时效性和可靠性不好保证
- 客户端埋点的痛病
- 支持的统计大多是简单计数,无法完成完整的多维分析功能
- 应用场景和产品举例
- 场景:常用于简单的pv统计,如网站pv、APP的DAU等宏观数据
- 第三方产品:umeng TalkingData Google Analytics
- 原理
- 可视化埋点:控件埋点(Mixpanel,诸葛IO),可视化埋点先通过界面配置哪些控件的操作数据需要收集
- 原理
- 参考手游APP的做法,把核心代码和配置、资源分开,在APP启动的时候通过网络更新配置和资源
- 在虚拟的可视化界面,对支持的控件类型的实例,点击配置事件(event),然后发布,配置通过后端接口直接下发给APP,所有安装有嵌入SDK的APP都会在启动时或者定时获取相应的配置。以后,真实的用户使用时,点击这个按钮,就会发送事件到后端
- 实现细节:
- 在嵌入了SDK的APP开启可视化埋点模式,与后端联通时,SDK会应后端的要求,定期(例如每秒)做一次截图,而SDK在为App截图的同时,会从keyWindow对象开始进行遍历它的subviews(),得到当前视图下所有 UIView、UIResponder对象的层级关系。对于屏幕上的任何一个UIView对象,如 Button、Textfield等它都有一条唯一的从keyWindow到它的路径,这个路径上每个节点,都由ClassName、它是父节点的第几个subview、.text()等属性的值等标识。相对于父节点的坐标、长宽高等可视化方面的信息,是作为这个节点的属性存在。
- 服务端根据截屏和可视化信息来重新进行页面渲染,并且根据控件的类型,来识别哪些控件是可以增加可埋点的,并且将之标识出来。
- 当使用者在后台的截屏画面上点击了某个可埋点的控件时,后台会要求使用者做一些事件关联方面的配置,并且将配置信息进行保存和部署。
- SDK 在启动或者例行轮询时拿到这些配置信息,则会通过.addTarget:action:forControlEvents:接口,为每个关联的控件添加的点击或者编辑行为的监听,并且在回掉函数里面调用 Sensors Analytics SDK 的接口发送相应事件的 track 信息。
- 优点
- 可视化埋点很好地解决了代码埋点的埋点代价大和更新代价大两个问题。
-
- 新增埋点在所有版本生效,不存在老版本迭代问题(只要老版本app有嵌入sdk)
- 不懂代码的产品运营人员也可以通过后台可视化界面配置统计埋点并实时下发到客户端生效
- 不足
- 可视化埋点能够覆盖的功能有限的,目前并不是所有的控件操作都可以通过这种方案进行定制
- 不能自定义设置事件属性
- 例如对于评论“提交”事件,并不能将评论的内容作为事件的属性进行上传
- 在上传事件时,就只能上传SDK自动收集的设备、地域、网络等默认属性,以及一些通过代码设置的全局公共属性了
- 数据传输的时效性和可靠性不好保证
- 客户端埋点的痛病
- 应用场景和产品
- 场景:
- 替代代码埋点,支持产品、运营等非技术人员管理埋点
- 活动/新功能快速上线迭代时的效果评估,可利用可视化埋点快速完成
- 第三方产品: 诸葛io MixPanel 神策数据
- 场景:
- 原理
- 无埋点(全埋点):(Heap Analytics,灵动分析, GrowingIO),可视化埋点是根据埋点配置来收集数据,而无埋点方案则是尽可能的收集所有控件的操作数据。 实现原理也很简单, 客户端添加扫描代码, 为每个扫描到的控件添加监听事件。 当事件被触发后,记录日志。
- 原理
- 在App中嵌入SDK,做统一的“全埋点”,将APP的操作尽量多的采集下来,然后通过界面配置的方式对关键行为进行定义,这样便完成了所谓的“无埋点”数据采集
- 事先在产品上埋一个 SDK
- 通过可视化的方式,生成配置信息,也就是事件名称之类的定义
- 将采集的数据按照配置重命名,进而就能做分析了
- 在App中嵌入SDK,做统一的“全埋点”,将APP的操作尽量多的采集下来,然后通过界面配置的方式对关键行为进行定义,这样便完成了所谓的“无埋点”数据采集
- 优点
- 解决了数据“回溯”的问题
- 例如,在某一天,突然想增加某个控件的点击的分析,如果是可视化埋点方案,则只能从这一时刻向后收集数据,而如果是“无埋点”,则从部署 SDK 的时候数据就一直都在收集了
- “无埋点”方案也可以自动获取很多启发性的信息,例如,“无埋点”可以告诉使用者这个界面上每个控件分别被点击的概率是多大,哪些控件值得做更进一步的分析等等
- 解决了数据“回溯”的问题
- 缺点
- 与可视化埋点一样,“无埋点”依然没有解决覆盖的操作有限问题,不能灵活地自定义属性
- 数据传输的时效性和可靠性不好保证
- 客户端埋点的痛病
- 由于所有的控件事件都全部搜集,可能会给服务器和网络传输带来更大的负载
- 与可视化埋点的区别
- 可视化埋点先通过界面配置哪些控件的操作数据需要收集
- “无埋点”则是先尽可能收集所有的控件的操作数据,然后再通过界面配置哪些数据需要在系统里面进行分析
- 应用场景和产品
- 场景:和可视化埋点相同
- 第三方产品:Heap Analytics Growing IO
- 原理
-
Google Measurement Protocol
上述的三种埋点都是在客户端埋点,都需要客户端嵌入sdk 为避免浪费用户流量,都需要定时或定量的批量打包发送数据
- 原理
- 在需要埋点/追踪事件的地方(客户端或服务端),以规定的格式/规范/协议,把相关的事件属性信息以及相关字段通过HTTP请求发送到指定的接收服务器
- 优点
- 实时发送数据,不存在数据延时
- 将线上和线下行为联系在一起
- 可同时从客户端和服务器发送数据
- 缺点
- 需要手动在代码中埋点
- 考虑到用户流量消耗问题,不可能把所有的用户事件都埋点
- 新的埋点需要发新版
- 原理
-
几种埋点的典型使用场景对比
- 举例:以电商APP的订单结算页面为例,当用户点击_去结算_按钮
- 可视化埋点与无埋点只能采集到用户在某时某刻点击了去结算
- 客户端单代码埋点能采集到去结算订单的金额,商品名称、用户等级等客户端可以获取的信息
- 服务端代码埋点可以采集到商品库存、成本等其他关联的信息
- 总结:
- 可视化埋点使用和部署比较简单,但数据获取能力有限
- 客户端代码埋点埋点复杂,能拿到在客户端保存的信息
- 服务端代码埋点能获取到事件以外的关联属性,但部署会影响线上业务代码逻辑和架构,对于这种外围信息,建议离线做join完成
- 举例:以电商APP的订单结算页面为例,当用户点击_去结算_按钮
| 埋点方式 | 数据时效 | 数据可靠(安全) | 数据可回溯 | 埋点成本 | 对业务的影响 | 用户流量开销 | 新埋点是否对所有客户端版本生效 |
|---|---|---|---|---|---|---|---|
| 传统代码埋点 | X | X | X | X | X | X | X |
| 可视化埋点 | X | X | X | √ | √ | X | √ |
| 无埋点 | X | X | √ | √ | √ | X | √ |
| Measurement Protocol | √ | √ | X | X | X | √ | X |
数据可回溯是指当上新的事件埋点统计后,支持对历史数据(埋点之前的日期)的统计,且不用回滚数据
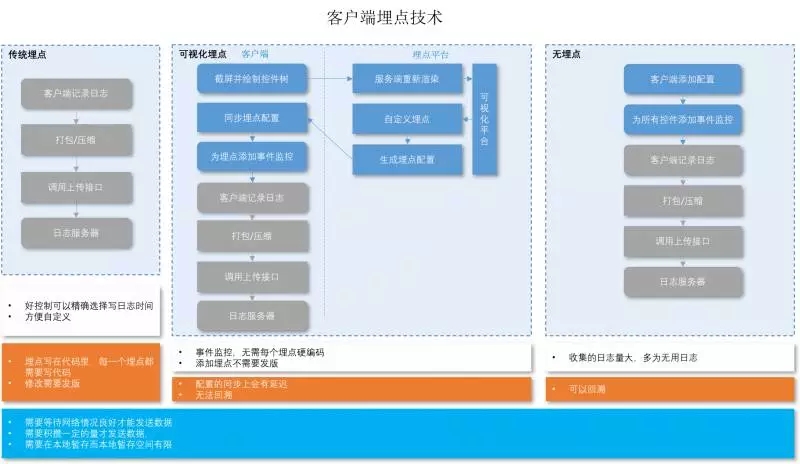
关于无埋点技术的参考文章:http://www.10tiao.com/html/209/201610/2651112803/1.html
数据收集的几大方面:
- General 数据(Data Overview):比哪安装量/卸载,手机型号,等等
- 下载量和使用量对比
- 实习统计/整体趋势
- 总用户数/新用户数/活跃用户/沉默用户/客户端用户数/实时用户数/App版本分布情况
- 每日(每周,每月)新增用户
- 用户的地域/组织分布
- 使用情况:总、平均使用时长,使用间隔,启动次数
- 设备类别/终端型号
- 分辨率
- 操作系统OS
- 浏览器类别
- 网络类别及运营商:WiFi,3G/4G…
- 用户的留存率和流失率
- 7天新增用户趋势
- 7天活跃用户趋势
- 改版功能活跃比
- 用户分析(People,User Behavior Analysis):
- Funnels (漏斗分析,by 按功能Steps的转化率,帮助分析哪个环节的转化率不够高,流失的用户具备什么特征)
- Retention (by Day/Week/Month, 留存能力)
- 实时统计Live view (by Events)
- 用户构成(周回流、连续活跃,近期流失)
- 用户分群(按区域,按Org,按功能使用情况)
- 用户分组/类
- 用户属性:男/女,年龄,职位,行业。。。
- 用户洞察(哪些用户因为什么原因流失)
- 用户的多维度交叉比较,版本交叉,人群交叉,同比,环比
- 各个「版本」的「注册」情况,各个「地域」的「购买」情况, 各个「功能」的「使用」情况,「功能」的使用次数,人员比例
- 用户变化趋势
- 用户留存、活跃度
- 渠道分布来源分析:
- App Store
- Website Download
- On-site Deploy
- App事件功能的统计(User Behavior Analysis,用户参与度,Event transformation statistical analysis):
- 某个功能的使用频率
- 功能/界面访问次数/人数/时长/错误率
- 登录(用户类别,地域,登录时间,Org,成功,失败(原因: 密码错,服务器忙,网络错误),网络类别)
- Message 发送失败(原因:网络错误,服务器忙)
- 界面点击便好(热图)
- 各功能的事件触发次数,触发用户数,人均触发次数
- 功能/界面启动次数
- 功能使用频率和时长(反应用户粘性)
- 好友列表、分组数量
- Add Favorite数量
- 消息发送/接收次数
- 电话发起/接收次数
- Voicemail Play/Delete次数
- Dial pad/search call out number
- Background/Foreground 切换
- 登录时长/登录失败次数/消息发送失败次数/电话发起接收失败次数
- 电话呼叫质量
- 性能和质量方面:
- 错误统计和分析
- 错误趋势,影响用户数
- 错误列表
- 性能分析: 网络异常/登录时间/UI反应时间
- 崩溃异常
数据收集的目的:
- 检测运营状况
- A/B Testing
- 效果/业务影响报告
- 问题和缺陷及时发现
- 反应趋势和分析改进
- Long Term version/In-sigh
- 用户关怀(Send Notification/Survey)
关于数据提交的方式:
- 启动时提交
- 即时提交
- 批量提交
- 缓存后WiFi网络情况下提交
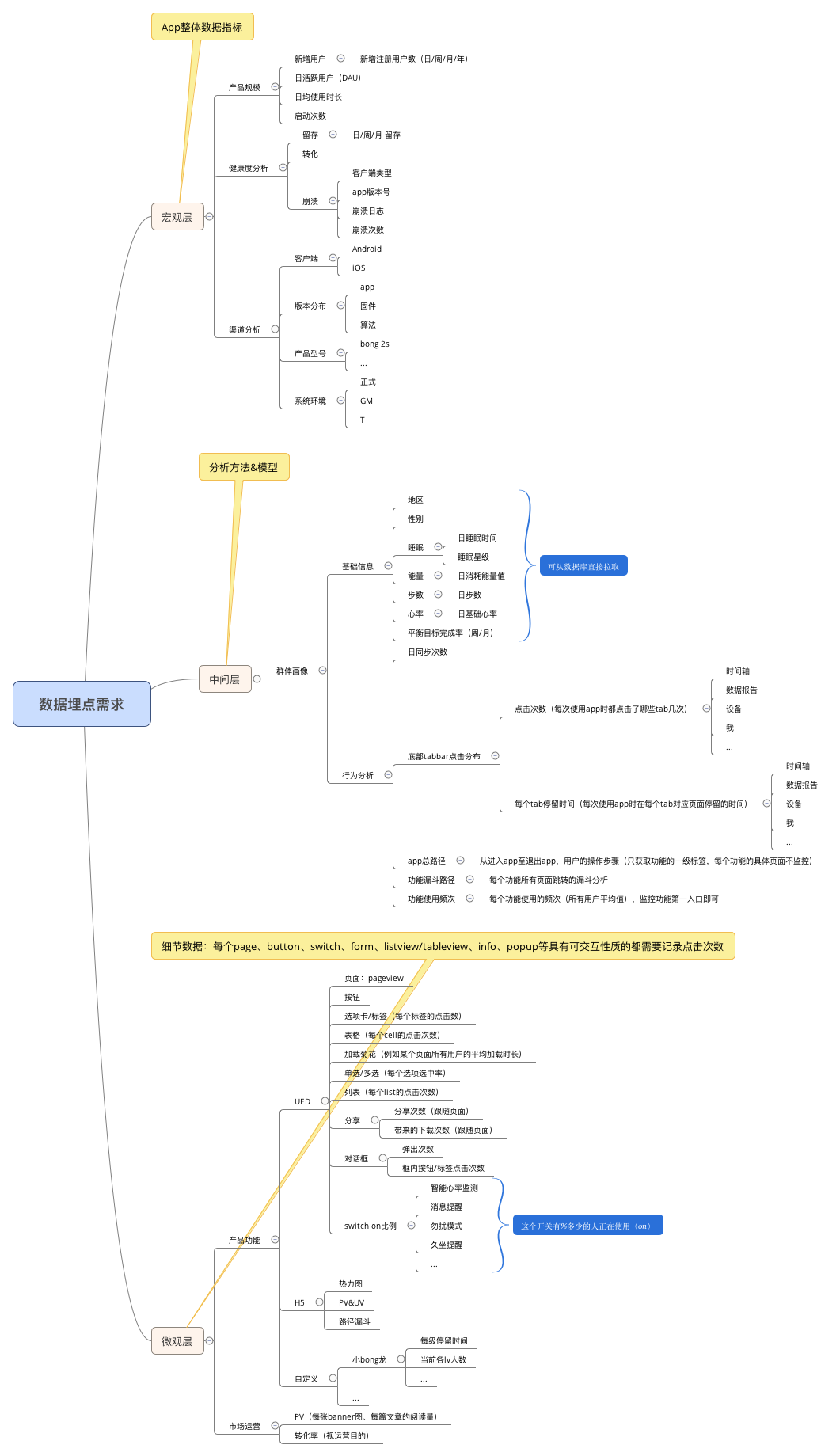
引用互联网资源关于 数据埋点需求的脑图:
获取更多资讯,欢迎关注微信公众号: atSting,或访问网址:www.atSting.com

